Understanding Structured Data in the Modern Search Landscape
The modern search landscape demands more than just keywords; it requires context. Schema markup, using the standardized vocabulary of Schema.org, provides search engines with explicit, machine-readable information about your content. This is crucial as search rapidly shifts from traditional SEO to Answer Engine Optimization (AEO), where engines aim to directly answer complex user queries rather than merely listing pages.
Observations indicate that structured data empowers algorithms to move beyond simple keyword matching, enabling them to understand the context, relationships, and entities within content. For example, without proper markup, a search engine might struggle to differentiate "Apple" the tech company from "apple" the fruit. This precision ensures content is interpreted correctly, leading to enhanced visibility. However, challenges persist:
- Ensuring accurate implementation across diverse pages.
- Adapting to rapidly evolving search standards.
For a comprehensive overview, see advanced implementation.
Essential Schema Types for Diverse Content Strategies
Effective schema markup implementation begins with selecting the appropriate schema types that align directly with your content and business objectives. For establishing a robust brand identity and local presence, Organization schema and LocalBusiness schema are foundational. The former defines your entity's official name, logo, and contact details, while the latter provides crucial geographical information, operating hours, and service areas. Field observations indicate that correctly implemented LocalBusiness schema significantly enhances visibility for geo-targeted searches, often powering knowledge panels and map results.
E-commerce platforms benefit critically from Product schema and Review schema. Product schema allows for detailed item specifications—such as price, availability, and SKU—to appear as rich snippets, directly influencing click-through rates. When paired with AggregateRating and Review schema, customer feedback and star ratings are prominently displayed, building consumer trust and guiding purchasing decisions. Practical experience shows a direct correlation between these rich results and improved conversion funnels.
To capture diverse informational search intent, Article schema is indispensable for blog posts, news, and guides, helping search engines categorize and display content effectively. For pages addressing common queries, FAQPage schema can generate interactive "People Also Ask" features or direct answers, providing immediate value to users.
Ultimately, identifying the right schema type necessitates a deep understanding of your specific business goals and the user journey. Technical data suggests that misaligned schema, even if syntactically correct, may fail to yield desired SERP enhancements. Therefore, content strategists must meticulously map their content assets to the most relevant and impactful schema definitions to unlock optimal visibility and user engagement.
Technical Formats: Choosing Between JSON-LD, Microdata, and RDFa
Choosing the right technical format for your schema markup implementation is a foundational decision with significant implications for efficiency and long-term maintenance. Currently, JSON-LD (JavaScript Object Notation for Linked Data) stands out as the preferred format for search engines, including Google.
JSON-LD is a JavaScript object embedded within a <script type="application/ld+json"> tag, typically placed in the <head> or <body> of an HTML document. Its "out-of-band" nature means it does not interfere with the visual rendering of the page or require direct manipulation of existing HTML elements. This separation of data from presentation makes JSON-LD incredibly flexible and easier for crawlers to parse without needing to reconstruct the page's DOM.
While JSON-LD dominates, Microdata and RDFa still have specific use cases, primarily within legacy systems. These formats embed schema directly into the HTML using attributes (e.g., itemscope, itemtype, itemprop). While functional, they tightly couple the markup with the HTML structure, which can complicate development and maintenance, especially on dynamic websites.
In my view, the shift towards JSON-LD isn't just about developer convenience; it is about reducing the potential for implementation errors that can hinder schema adoption. Practical experience shows that technical simplicity often leads to better SEO outcomes. A common mistake I've encountered with inline formats is the difficulty in scaling updates across large sites, leading to fragmented and inconsistent markup. Updating a single piece of Microdata often requires touching multiple HTML elements.
Comparing maintenance requirements, JSON-LD offers a significant advantage. Its centralized block of code is easier to review, debug, and update, ensuring your structured data remains consistent and accurate as your content evolves. Microdata and RDFa, being dispersed throughout the HTML, demand more rigorous and time-consuming maintenance, increasing the risk of outdated or conflicting information over time.
A Step-by-Step Framework for Schema Markup Implementation and Validation
Implementing schema markup effectively requires a methodical approach that extends beyond simply generating code. It demands precision in deployment, vigilance in error detection, and foresight for scalability. For SEO specialists and web developers, a structured framework is indispensable for ensuring robust, error-free, and impactful structured data.
The Structured Data Deployment Cycle (SDDC)
Practical experience shows that a systematic framework significantly reduces implementation errors and enhances the long-term maintainability of structured data. The Structured Data Deployment Cycle (SDDC) offers a five-stage process designed to guide technical SEO professionals through the complexities of schema markup, from initial code generation to large-scale validation and deployment.
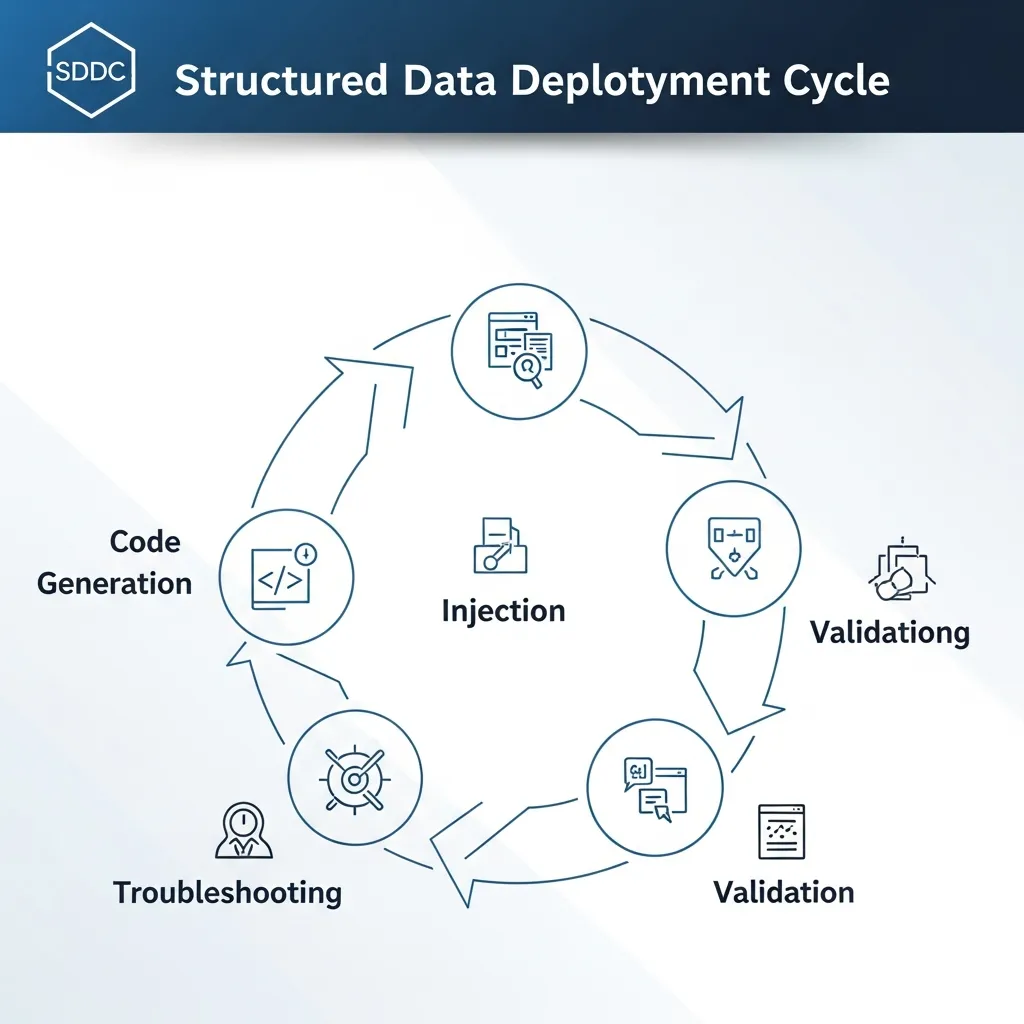
1. Code Generation: Precision Through Tools and Scripts
The foundation of any successful schema implementation is correctly formed JSON-LD code. While the goal is always valid code, the method of generation often depends on the project's scale and available resources.
- Automated Tools and CMS Plugins: For simpler schema types or smaller sites, tools like Schema.org generators (e.g., Google's Structured Data Markup Helper) or CMS plugins (e.g., for WordPress or Shopify) can quickly produce basic JSON-LD. These tools are excellent for accelerating initial deployment and ensuring adherence to fundamental syntax. However, they can sometimes generate generic or bloated code, potentially missing opportunities for richer, more specific markup. Field observations indicate that relying solely on these for complex schema can lead to a "lowest common denominator" approach.
- Manual Scripting and Custom Development: For intricate schema types or highly customized data, direct JSON-LD scripting is often necessary. This involves crafting the
@context,@type, and relevant properties manually. While more time-consuming, manual scripting offers unparalleled flexibility and precision. It allows for meticulous control over every data point, enabling the creation of highly specific and nested schema that automated tools might overlook. This approach is particularly valuable for unique content models or when aggregating data from multiple sources.
2. Injection Strategy: HTML Head vs. Tag Management Systems
Once the JSON-LD code is generated, the next step is injecting it into the website's HTML. The choice between direct HTML embedding and using a Tag Management System (TMS) like Google Tag Manager (GTM) depends on development cycles and performance considerations.
- Direct Injection into HTML
<head>: Placing the<script type="application/ld+json">block directly within the<head>section is the most straightforward method. This ensures the schema is present in the initial page load, making it immediately available to search engine crawlers. This approach is generally preferred for critical, static schema fundamental to the page's identity (e.g.,WebPage,Article, orProduct). The primary challenge lies in requiring developer intervention for changes. - Tag Management Systems (TMS): Utilizing a TMS offers a powerful alternative, granting marketing and SEO teams greater control over deployment without constant developer dependency. With GTM, JSON-LD scripts can be deployed as custom HTML tags triggered by specific page views. This method excels in scenarios requiring dynamic data injection or rapid deployment of changes. However, technical data suggests that deploying schema asynchronously via a TMS can introduce a slight delay in its availability to crawlers. While search engines are adept at processing asynchronously loaded content, direct embedding often provides the most robust signal.
Pro Tip: For optimal performance and reliability, prioritize injecting core, static schema directly into the HTML. Use a TMS for dynamic, supplementary schema, or for testing purposes where flexibility outweighs the minor performance trade-off. Always ensure the TMS tag fires before the page renders its main content to provide crawlers with the earliest possible access.
3. Troubleshooting Common Syntax Errors
Even with careful generation, errors can creep into JSON-LD. Identifying and rectifying these is crucial for successful validation. Common syntax pitfalls include:
- Missing Commas: JSON is unforgiving; a missing comma between properties or array elements is a frequent culprit.
- Incorrect Braces or Brackets: Mismatched
{}(objects) or[](arrays) can break the entire structure. - Typos in Property Names: Schema.org properties are case-sensitive.
imageis different fromImage, andauthorfromcreator. - Incorrect Nesting: Properties must be correctly nested within parent objects. For example, an
authorobject belongs within anArticleobject, not at the root level. - Invalid Data Types: Assigning a string value where a URL is expected, or a number where a boolean is required, will trigger errors.
Leverage integrated development environments (IDEs) with JSON validation, or copy-paste your JSON-LD into online JSON validators (like JSONLint) before validating with Google's tools.
4. Validation: Ensuring Rich Result Eligibility and Schema Compliance
After injecting the schema, thorough validation is non-negotiable. This step confirms that the code is syntactically correct and semantically meaningful.
- Google's Rich Results Test: This is the primary tool for determining if your structured data is eligible for specific rich results in Google Search. It simulates how Google parses your page and highlights critical errors, warnings, or opportunities for enhancement. It is essential for verifying rich result-eligible types like
Product,Recipe,FAQPage, andEvent. - Schema Markup Validator (schema.org): While the Rich Results Test focuses on Google's specific features, the Schema Markup Validator provides a broader validation against the entire schema.org vocabulary. It is invaluable for checking the correctness of schema types that provide context but might not lead to a rich result (e.g.,
OrganizationorLocalBusiness).
Regular validation, especially after content or template updates, is crucial. Integrating validation into deployment workflows prevents regressions and ensures consistent data quality.
5. Scaling Implementation: Dynamic Templates for Large-Scale Websites
For large websites with thousands of pages, manual implementation is impractical. Dynamic templating is the cornerstone of scalable structured data.
- Leveraging CMS and Templating Engines: Modern Content Management Systems and templating engines (e.g., Jinja, Liquid, Twig) allow developers to create reusable JSON-LD templates. These templates contain placeholders for dynamic content populated by the CMS database. For example, a single
Productschema template can automatically populate unique names, prices, and images for every product page. - Benefits: This approach ensures consistency across an entire site, drastically reduces manual effort, and minimizes the risk of human error. Updates to the schema structure only need to be applied to the template to propagate across all relevant pages.
- Challenges: Initial setup requires close collaboration between SEO specialists and developers to map content fields to schema properties accurately. Once established, this system is a powerful asset for maintaining high-quality structured data at scale.
Advanced Techniques: Competitor Analysis and Gap Identification
Leveraging competitive intelligence is paramount for pushing schema markup beyond basic implementation. Competitor analysis allows SEO professionals to uncover advanced strategies and identify missed opportunities.
To reverse-engineer competitor schema, utilize tools like Google's Rich Results Test or the Schema.org Validator. Input competitor URLs and meticulously examine their implemented schema types and properties. Look beyond the obvious; scrutinize how they nest entities (e.g., a Review within a Product within an Offer). When applying this method, I've often found that competitors frequently overlook nested schema for complex entities, leaving significant rich result potential untapped.
Identifying 'schema gaps' involves comparing your content against competitor structured data. If a competitor's recipe page consistently generates rich results but your similar content lacks the corresponding Recipe schema, that is a prime gap. Focus on content types where rich results are common, such as FAQPage, HowTo, Product, or Event.
Prioritizing high-impact schema types for maximum ROI is crucial. In my view, the most effective approach is to focus on schema that directly influences visible rich results and user interaction, thereby impacting click-through rates. For instance, Product schema is vital for e-commerce, while FAQPage can dominate informational query results.
Finally, integrate your structured data with Knowledge Graph optimization. Consistent and accurate entity identification through properties like sameAs (linking to Wikipedia or social profiles) and url helps search engines build a robust understanding of your brand. A common mistake I've encountered is inconsistent sameAs values across different pages, which can hinder Knowledge Graph interpretation. Ensuring a consistent canonical URL for an entity property can significantly improve entity recognition, often boosting branded search visibility.
Monitoring and Measuring the Impact of Structured Data
Following schema markup implementation, continuous monitoring is vital to ensure your structured data remains effective and error-free. Leverage Google Search Console's Enhancements reports to track the health of your rich results, promptly identifying any errors or warnings that could prevent their display. Field observations indicate that consistent vigilance here prevents significant visibility drops.
Beyond mere health, analyzing the correlation between rich results and Click-Through Rate (CTR) is paramount for quantifying impact. Use GSC's Performance report to filter by rich result type, comparing CTRs for pages with and without rich snippets to demonstrate their value. Practical experience shows a direct link between rich result appearance and improved user engagement. Furthermore, setting up custom alerts for schema validation errors ensures immediate awareness of critical issues. This proactive approach minimizes downtime and maintains the integrity of your schema markup implementation, ultimately showcasing a clear ROI.
The Role of Structured Data in AI Search and Voice Optimization
Structured data is truly the language of AI, directly feeding Large Language Models (LLMs) to power sophisticated, AI-driven search results with precise answers. For voice optimization, Speakable schema becomes crucial, instructing AI on content suitable for audio output, alongside clear entity definition.
A common mistake I've encountered is implementing basic schema without considering its deeper role in AI comprehension; this significantly limits its true potential. In my view, neglecting this structured context is like trying to communicate without grammar. Structured data is, unequivocally, the future web's foundational language, enabling seamless interaction between users and intelligent systems.
Building a Sustainable Structured Data Strategy
In my experience, a common mistake is treating schema as a static, one-time setup, overlooking its iterative lifecycle. I believe a sustainable structured data strategy demands continuous validation and dynamic adaptation. Embrace this commitment. Start by auditing your existing schema and mapping out a plan for ongoing optimization.
Frequently Asked Questions
What is the best format for schema markup implementation?
JSON-LD is the preferred format for search engines like Google because it is easy to implement and maintain without affecting the page's visual rendering.
How do I validate my schema markup?
You can use Google's Rich Results Test to check for rich snippet eligibility and the Schema Markup Validator at schema.org for general syntax and vocabulary compliance.
Why is schema markup important for AI search?
Structured data provides machine-readable context that helps Large Language Models (LLMs) and AI search engines understand entities and relationships within your content.
What is the Structured Data Deployment Cycle (SDDC)?
The SDDC is a five-stage framework consisting of Code Generation, Injection, Troubleshooting, Validation, and Scaling to ensure robust schema implementation.