The Critical Role of Chunking in Retrieval-Augmented Generation
In Retrieval-Augmented Generation (RAG) systems, content chunking RAG is a foundational preprocessing step that directly influences retrieval efficacy. Unlike general UX chunking, RAG chunking segments source documents into discrete, semantically meaningful units, prioritizing granular, contextually rich segments for vectorization and search.
Field observations indicate that optimal chunking profoundly impacts vector database indexing, determining retrieval precision. It dictates how effectively information fits within the LLM context window, preventing truncation and minimizing noise. Consider a dense technical manual: poor chunking leads to irrelevant retrievals. This step is crucial for optimizing content in RAG.
Key challenges that intelligent chunking addresses include:
- Ensuring semantic relevance.
- Maximizing data utility within the LLM context.
- Improving overall system accuracy.
The Chunking Dilemma: Balancing Granularity and Semantic Context
The efficacy of any RAG system hinges significantly on how well its content is segmented. This seemingly straightforward preprocessing step presents a fundamental chunking dilemma: balancing the need for granular precision with sufficient semantic context. Imagine a complex legal document; chunking it incorrectly could lead to a critical clause being missed or misinterpreted by the LLM.
This balancing act presents several challenges:
- Optimizing for both retrieval precision and comprehensive context.
- Mitigating the 'Lost in the Middle' phenomenon.
- Controlling computational and financial overhead.
The core trade-off lies between small chunks and large chunks. Small chunks, often consisting of just a few sentences, offer high retrieval precision because their embeddings are highly specific. However, they can lack the necessary surrounding context for an LLM to fully understand and synthesize information, potentially leading to fragmented responses.
Conversely, large chunks provide ample context but may introduce noise, reducing retrieval precision by embedding less relevant information alongside the core answer. Many perceive chunking as a simple text-splitting task, but in reality, the most effective approach requires a nuanced understanding of information flow.
Poor chunking, particularly with excessively large segments, can lead to the 'Lost in the Middle' phenomenon. This established LLM behavior indicates that models often prioritize information presented at the beginning and end of their context window, neglecting crucial details buried in the middle of long chunks. Consequently, even if relevant information is retrieved, the LLM might fail to utilize it effectively.
Beyond accuracy, chunking profoundly impacts computational overhead and embedding costs. Smaller chunks mean a greater number of individual embeddings, leading to increased storage requirements for vector databases and higher API costs for embedding services. A common mistake encountered across various RAG implementations is underestimating this cascading impact. While larger chunks reduce the number of embeddings, they demand more computational resources from the LLM during inference to process the extended context, potentially increasing latency and operational expenses.
Comprehensive Content Chunking Strategies for RAG Systems
Navigating the complexities of information retrieval in RAG systems demands a sophisticated approach to content segmentation. While the previous discussion highlighted the challenges, this section delves into the advanced content chunking RAG strategies employed to optimize retrieval and synthesis, moving beyond simplistic methods to embrace more intelligent, context-aware techniques.
Fixed-Size Chunking: Simplicity with Caveats
Fixed-size chunking is the most straightforward method, segmenting documents into predetermined token or character counts. Its primary advantages lie in its simplicity of implementation and predictable chunk sizes, which can be beneficial for uniform processing and indexing.
Field observations indicate that this approach is most suitable for highly structured documents where semantic boundaries are less critical, or for initial rapid prototyping. However, its significant limitation is the arbitrary truncation of text, often splitting sentences, paragraphs, or even code blocks in the middle. This can sever crucial semantic connections, leading to fragmented information and poor retrieval quality, as the retrieved chunk might lack essential context from the preceding or succeeding text.
Recursive Character Splitting: The Current Standard for Cohesion
To overcome the arbitrary nature of fixed-size chunking, Recursive Character Splitting has emerged as a widely adopted, industry-standard approach. This method iteratively splits text based on a hierarchy of delimiters, typically starting with larger units like paragraphs, then sentences, and finally words or characters if necessary.
The process attempts to maintain semantic integrity by prioritizing natural breakpoints. For instance, it will first try to split by \n\n (double newline for paragraphs), then \n (single newline), then (space for words), and so on. This recursive nature ensures that larger, coherent blocks are preserved where possible, only breaking them down further when they exceed the desired chunk size. Technical data suggests this method offers a robust balance between processing efficiency and the preservation of contextual meaning, making it a reliable choice for diverse document types.
Semantic Chunking: Meaning-Driven Segmentation
Moving beyond character-based splits, Semantic Chunking leverages the power of embedding models to identify natural breakpoints based on the meaning of the text. Instead of relying on delimiters, this strategy generates embeddings for smaller text units (e.g., sentences) and then uses similarity measures or clustering algorithms to group semantically related units together.
Chunks are formed where there are significant shifts in meaning, ensuring that each resulting chunk represents a cohesive idea or topic. This method is particularly effective for unstructured text where explicit structural cues are scarce. While more computationally intensive due to the embedding generation and comparison steps, practical experience shows that semantic chunking often yields higher quality, more relevant chunks, directly improving retrieval accuracy by providing the LLM with contextually rich information.
Parent-Child (Hierarchical) Chunking: Decoupling Retrieval and Synthesis
One of the most advanced strategies for complex RAG systems is Parent-Child Chunking, also known as hierarchical chunking. This approach decouples the data used for initial retrieval from the data used for final synthesis.
Small, concise "child" chunks (e.g., individual sentences or key phrases) are created and embedded for fast and precise retrieval. Once a relevant child chunk is identified, its larger "parent" chunk (e.g., the full paragraph or section it belongs to) is retrieved and passed to the LLM for synthesis. This strategy effectively mitigates the "Lost in the Middle" phenomenon by allowing for granular retrieval without sacrificing the broader context needed for accurate generation. It ensures the LLM receives comprehensive information, even when the initial query matches only a small, specific detail.
Agentic Chunking: LLM-Guided Segmentation
Agentic Chunking represents the cutting edge of content segmentation, employing an LLM itself to intelligently segment complex documents based on intent, structure, or specific information types. Instead of predefined rules, an LLM analyzes the document, understands its logical flow, and determines optimal chunk boundaries.
For example, an agentic chunker could identify distinct sections in a research paper (introduction, methodology, results) or extract specific entities and their descriptions from a legal document. This method offers unparalleled flexibility and precision, creating highly tailored chunks that align perfectly with the document's inherent structure and potential query patterns. While requiring more computational resources and careful prompt engineering, agentic chunking can significantly enhance retrieval for highly nuanced or domain-specific queries, as it can adapt to the semantic content in ways fixed rules cannot.
Sliding Windows and Overlap: Preventing Context Loss at Boundaries
Regardless of the primary chunking strategy employed, Sliding Windows and Overlap is a crucial complementary technique to prevent context loss at chunk boundaries. When a document is segmented, there is always a risk that a critical piece of information or a semantic link might be split across two adjacent chunks.
By introducing an overlap—where a portion of the preceding chunk is included at the beginning of the next chunk—the system ensures that the LLM has continuous context, even when processing information that spans multiple chunk divisions. The optimal overlap size is often a tunable hyperparameter, balancing the need for context against the introduction of redundancy and increased processing load. Field observations suggest that a 10-20% overlap of the chunk size is a common starting point for many RAG implementations.
Pro Tip: When implementing overlap, consider the nature of your content. For highly sequential narratives or code, a larger overlap might be beneficial. For discrete, self-contained facts, a smaller overlap or even none might suffice to reduce redundancy.
The RAG Chunking Strategy Navigator
Selecting the optimal chunking strategy is not a one-size-fits-all decision. Use this checklist to guide your choices:
| Consideration | Fixed-Size | Recursive Char | Semantic | Parent-Child | Agentic | Sliding Window |
|---|---|---|---|---|---|---|
| Document Structure (Highly structured) | High | Medium | Low | Low | Medium | N/A |
| Document Structure (Unstructured/Complex) | Low | Medium | High | High | Very High | N/A |
| Semantic Integrity (Critical) | Low | Medium | High | High | Very High | N/A |
| Retrieval Granularity (Fine-grained) | Medium | Medium | High | High (Child) | High | N/A |
| Synthesis Context (Broad) | Low | Medium | High | High (Parent) | High | N/A |
| Computational Cost | Low | Medium | High | Medium | Very High | Low |
| Context Loss Prevention | N/A | N/A | N/A | N/A | N/A | High |
Technical Implementation Guide: LangChain and LlamaIndex Patterns
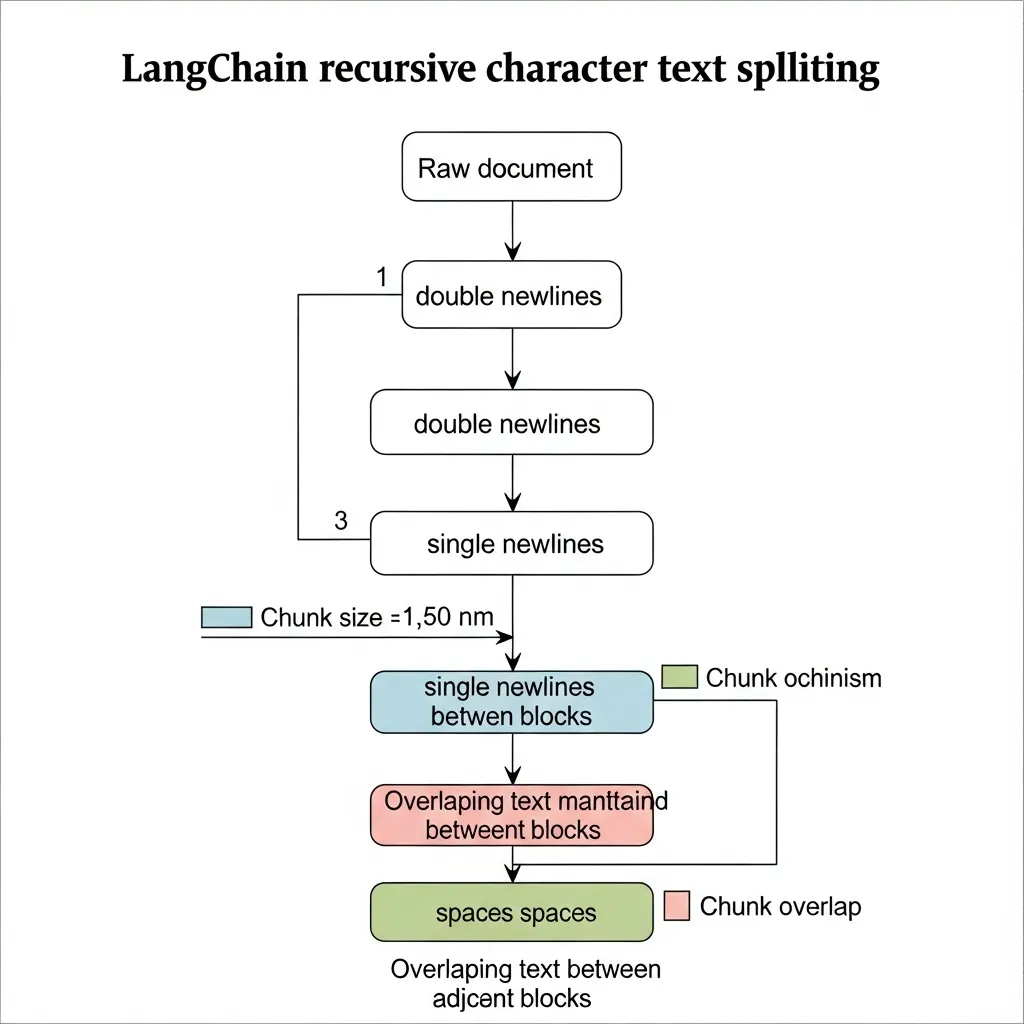
Implementing advanced chunking strategies necessitates leveraging robust libraries for optimal RAG performance. For recursive character splitting, LangChain's RecursiveCharacterTextSplitter serves as a foundational tool. It systematically segments documents using a prioritized list of delimiters, such as double newlines then single newlines, ensuring that natural document structures are preserved. This approach minimizes the risk of semantically incoherent breaks often seen with simplistic fixed-size methods, making it an industry standard for maintaining context.
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Max size for each chunk
chunk_overlap=200, # Overlap to maintain context across boundaries
separators=["\n\n", "\n", ". ", " ", ""] # Hierarchical delimiters for logical breaks
)
For hierarchical parent-child retrieval, LlamaIndex's HierarchicalNodeParser offers a sophisticated pattern. This strategy generates smaller, optimized "child" chunks for precise retrieval, while simultaneously retaining links to larger "parent" chunks that provide broader contextual understanding during synthesis. Practical experience shows this design significantly enhances both the relevance of retrieved information and the coherence of generated responses, effectively mitigating the "lost in the middle" problem by offering context on demand.
python
from llama_index.node_parser import HierarchicalNodeParser
from llama_index.text_splitter import SentenceWindowNodeParser # Or other child splitter
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2048, chunk_overlap=256)
child_splitter = SentenceWindowNodeParser(window_size=3) # Creates smaller, context-rich windows
node_parser = HierarchicalNodeParser(
chunk_size=512, # Base chunk size before parent-child logic
chunk_overlap=128,
parent_splitter=parent_splitter,
child_splitter=child_splitter,
)
Configuring semantic splitters represents a frontier in chunking, moving beyond structural cues to leverage meaning. This involves utilizing the latest embedding models—such as those offered by OpenAI, Cohere, or various open-source initiatives like those from Hugging Face—to identify semantically coherent boundaries.
The process typically involves embedding smaller text segments (e.g., sentences) and then applying clustering or change-point detection algorithms on their vector representations. This ensures chunks encapsulate complete ideas, even if they span traditional paragraph breaks, thereby enhancing the semantic fidelity and overall relevance of retrieved content for the LLM.
Selecting Chunking Methods Based on Document and Query Type
Choosing the optimal content chunking RAG method is paramount for system effectiveness, moving beyond generic strategies to specialized approaches. For technical documentation and API references, which are highly structured, maintaining logical units is critical. Small, self-contained chunks representing a function, parameter, or code example work best. In my experience, chunking these too broadly often leads to irrelevant details cluttering the retrieval results.
Conversely, narrative or long-form legal documents demand preserving extensive contextual flow. Recursive character splitting with larger chunk sizes and significant overlaps is generally more effective, allowing the LLM to synthesize information from broader passages. Overlooking the need for greater context in such documents is a common pitfall that negatively impacts response quality.
Query intent also heavily dictates chunking requirements:
- Factoid queries benefit from smaller, precise chunks.
- Analytical queries requiring synthesis necessitate medium-sized chunks offering enough context for comparison.
- Summarization queries may require larger chunks or even entire sections.
A common mistake is using a one-size-fits-all chunk size, which degrades performance across diverse query types; dynamically adjusting based on predicted intent significantly improves accuracy.
Evaluating Chunking Effectiveness: Metrics and Frameworks
Effective evaluation of chunking strategies is paramount for optimizing RAG system performance. For assessing retrieval accuracy, practitioners typically employ metrics such as:
- Hit Rate: Indicates if any relevant chunk was retrieved.
- Mean Reciprocal Rank (MRR): Evaluates the position of the first relevant document.
- Precision@K: Measures the proportion of relevant chunks among the top K retrieved results.
Beyond raw retrieval, the quality of generated responses is critical. Frameworks like RAGAS are essential, leveraging LLMs to evaluate Faithfulness (verifying factual consistency with retrieved context) and Answer Relevancy (ensuring the answer directly addresses the query). Field observations indicate that the most robust validation comes from A/B testing different chunk sizes and methodologies directly within a production environment. This provides empirical data on user experience and system performance, guiding iterative improvements for optimal RAG outcomes.
Common Pitfalls to Avoid in RAG Data Preprocessing
Even with sophisticated chunking strategies, RAG performance can falter due to common preprocessing errors. A significant pitfall is ignoring metadata; stripping headers, titles, or other contextual attributes during chunking removes vital cues, leading to less precise retrieval. In my experience, this often causes a substantial drop in semantic relevance by detaching chunks from their original document context.
Another issue is over-reliance on fixed-size windows without overlap, which arbitrarily splits critical information and fragments semantic units, thereby losing crucial inter-chunk relationships. Furthermore, inconsistent preprocessing between your indexing and query pipelines creates a mismatch. This inconsistency is a subtle but critical error that directly hinders accurate document matching and requires meticulous alignment.
Future-Proofing Your RAG Pipeline with Intelligent Chunking
Future-proofing your content chunking RAG pipeline demands a shift from static, fixed-size chunks to dynamic, context-aware strategies. This intelligent approach adapts to content structure and query intent, moving beyond rudimentary splits.
In my experience, a common mistake practitioners make is assuming one chunking method fits all data; this often leads to a significant drop in retrieval accuracy for diverse datasets. RAG optimization is an iterative journey, not a one-time configuration. The most resilient systems emerge from continuously experimenting with hybrid chunking approaches, blending techniques like semantic and hierarchical methods. This adaptability ensures sustained performance. Start by applying A/B testing frameworks to compare dynamic chunking strategies in your next RAG iteration.
Frequently Asked Questions
What is content chunking RAG?
Content chunking RAG is the process of breaking down large documents into smaller, semantically meaningful segments to improve the accuracy and efficiency of retrieval-augmented generation systems.
Why is chunking important for RAG?
It ensures that the most relevant information is retrieved for the LLM, prevents context window overflow, and reduces noise, leading to more accurate and coherent AI responses.
What is the best chunking strategy for RAG?
There is no one-size-fits-all, but Recursive Character Splitting is the industry standard, while Semantic and Parent-Child chunking offer higher precision for complex datasets.
How does chunking affect LLM costs?
Smaller chunks increase vector storage and embedding API costs, while larger chunks increase computational costs and latency during the LLM inference phase.