The Shift Toward Semantic Understanding in Modern Search
The landscape of digital search has undergone a profound transformation. What once relied predominantly on keyword matching has evolved into a sophisticated quest for semantic understanding, driven by advancements in artificial intelligence. Modern search engines no longer merely scan for identical word strings; instead, they strive to comprehend the underlying entities—people, places, things, and concepts—and their intricate relationships, mirroring human cognition.
This fundamental shift necessitates a new approach to content optimization. AI search engines leverage structured data as their primary mechanism for building context. By consuming machine-readable information embedded within webpages, these algorithms construct comprehensive knowledge graphs. This contextual framework enables them to disambiguate terms, identify attributes, and establish connections between concepts, moving far beyond surface-level keywords to infer true user intent. For instance, a search for “jaguar” can now differentiate between the animal and the car brand based on surrounding contextual data.
The advent of large language models (LLMs) has significantly amplified the importance of this machine-readable information. LLMs, which power many generative AI search experiences, depend on precisely defined structured data to generate accurate, contextually relevant, and authoritative responses. Observations indicate that content lacking this semantic richness struggles to be fully comprehended by these advanced systems.
To thrive in this evolving environment, content creators must focus on:
- Overcoming inherent ambiguity in search queries.
- Building robust, machine-understandable entity relationships.
- Ensuring AI systems can accurately interpret content.
This strategic pivot toward structured data for AI search is crucial for ensuring your digital presence is not just found, but truly understood by the next generation of search engines.
How AI Search Engines Process Structured Information
AI search engines have fundamentally shifted from keyword matching to semantic understanding, a process heavily reliant on structured information. At the core of this transformation are Knowledge Graphs (KGs)—vast networks that map entities (people, places, concepts) and their intricate relationships. These KGs serve as the foundational intelligence layer for generative AI responses, allowing models to synthesize information from diverse sources into coherent, contextually rich answers rather than merely providing a list of links.
The explicit nature of structured data significantly reduces ambiguity for AI crawlers. Unlike unstructured text, where a term like “jaguar” could refer to an animal, a car, or an operating system, structured data uses precise schema types and properties (e.g., schema.org/Vehicle or schema.org/Animal). This clear categorization eliminates guesswork, enabling AI to accurately interpret a page’s meaning and context.
To implement these technical standards effectively, it is helpful to start by learning the JSON-LD basics for SEO.
Effectively, structured data for AI search bridges the gap between unstructured content and AI-ready data. While AI models possess advanced natural language processing capabilities, interpreting raw text is computationally intensive and prone to subtle errors. By providing machine-readable annotations, structured data pre-processes and organizes information into a format AI can consume with maximum efficiency. This ensures that your content’s most critical entities and relationships are unequivocally communicated, enhancing its visibility in AI-generated summaries and answers.
Critical Schema Types for Enhancing AI Visibility
To guide AI search engines toward a comprehensive understanding of your content, strategically implementing specific schema types is paramount. These structured data annotations serve as explicit signals, helping AI models move beyond surface-level text analysis to grasp the core entities, relationships, and transactional intentions embedded within your digital assets. This precision significantly enhances your visibility in AI-driven search results and generative AI overviews.
Beyond textual data, you can improve how search engines index your visual assets when you apply schema for images and video
Establishing entity identity is foundational for AI search, which is why Organization and Person schema are critical. By explicitly defining your business as an Organization or an individual as a Person, you provide AI with unambiguous data points. This includes official names, contact information, social media profiles, and links to related entities. Consistent and comprehensive entity markup allows AI to accurately attribute content, consolidate information from disparate sources, and build a robust profile within its Knowledge Graph. For content creators, leveraging Person schema to identify authors with their credentials directly supports the AI’s assessment of expertise and authoritativeness.
For companies with a physical presence, it is vital to improve local SEO with LocalBusiness schema
For businesses engaged in e-commerce or service provision, Product and Review markup are indispensable for transactional AI queries. These schema types enable AI to quickly extract crucial details such as product names, unique identifiers (e.g., GTIN, SKU), pricing, availability, and aggregate ratings. Technical data suggests that well-implemented Product schema can significantly improve the chances of your offerings appearing in AI-generated shopping recommendations or comparative analyses.
Online retailers can significantly improve their visibility when they boost e-commerce SEO with product schema
Capturing attention in featured AI Overviews or direct answer snippets relies heavily on schema types like FAQPage and HowTo. FAQPage schema is designed to structure question-and-answer pairs, allowing AI to directly extract and present concise, authoritative answers to user queries. Similarly, HowTo schema breaks down processes into structured steps, including materials, tools, and estimated time. Content augmented with these schema types often sees enhanced visibility in generative AI features, as they directly feed the AI’s need for structured, digestible information.
Structuring your content for direct answers helps you use schema for FAQs
It is also beneficial to follow a guide to implement HowTo schema
Pro Tip: While implementing these schema types, ensure data consistency across your site and with your Knowledge Graph entries. Tools like Planik.io can assist in validating your structured data against current standards, ensuring AI crawlers can correctly interpret your semantic footprint.
Advanced Implementation: Architecting Data for AI Comprehension
The journey into structured data for AI search begins with foundational schema types, but true mastery lies in the sophisticated orchestration of semantic information. Moving beyond basic entity identification, the goal is to architect a data layer that enables AI to comprehend complex relationships, context, and the full semantic tapestry of your digital presence.
Mastering JSON-LD Nesting for Complex Relationships
At the heart of advanced implementation is the strategic use of JSON-LD nesting. While basic schema might declare an Article with an author and publisher, AI search engines gain deeper insights when these relationships are richly defined. Nesting allows you to embed one structured data object within another, creating a hierarchical and interconnected graph of entities and their attributes.
Consider a product page on Planik.io that features a software solution. Instead of simply declaring a Product type, you can nest its offers (pricing, availability), aggregateRating (reviews), and link to related SoftwareApplication features. This level of detail transforms isolated data points into a coherent narrative that AI can parse for sentiment, feature comparisons, and user intent.
Observations indicate that AI systems excel at processing these interconnected data graphs. For instance, when an AI encounters a Course schema, nesting educationalCredentialAwarded, hasCourseInstance, and coursePrerequisites provides a comprehensive view. This granular structuring enables AI to answer highly specific user queries by accurately matching nested properties. Technical data suggests that well-nested JSON-LD significantly reduces ambiguity for AI models, leading to more precise content retrieval and higher confidence scores in generative search outputs.
For a more detailed look at hierarchical data, explore our article on nested JSON-LD advanced schema
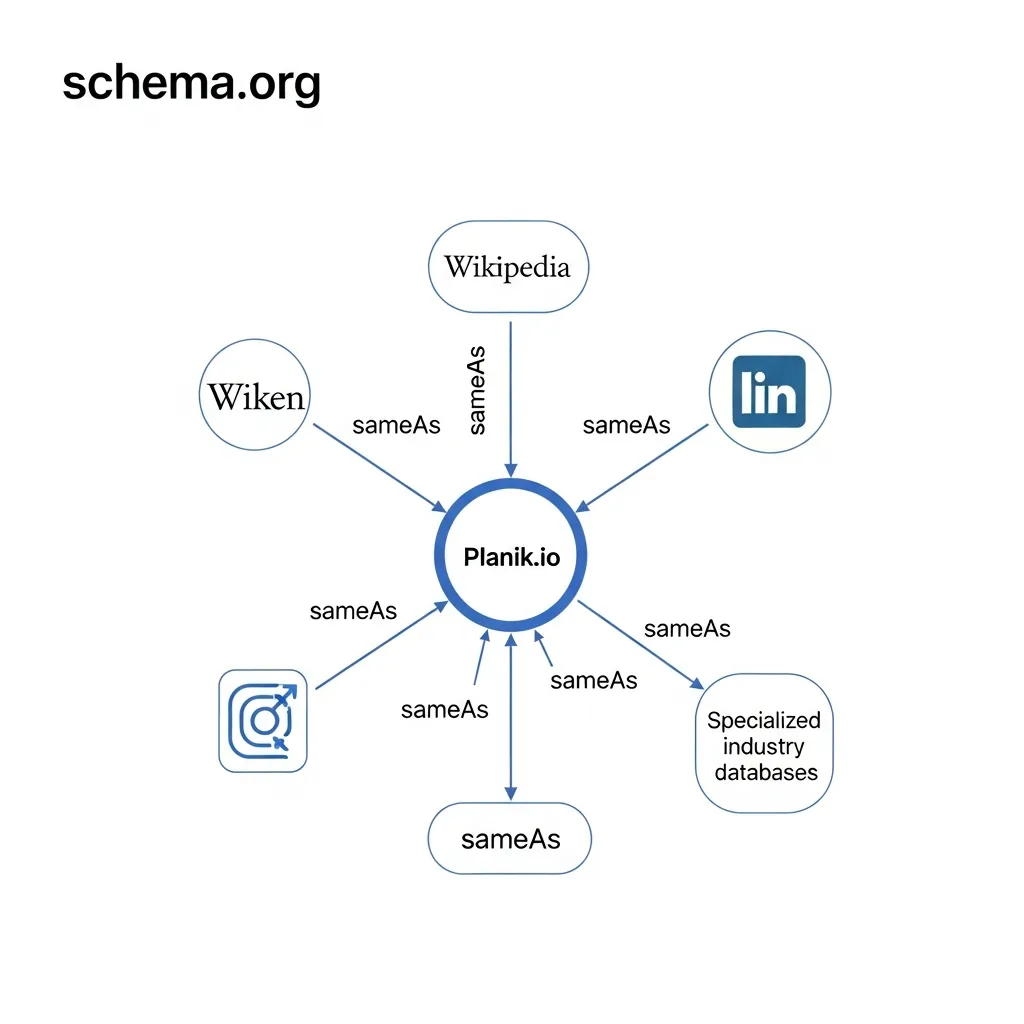
Linking to External Authoritative Nodes: sameAs and about
For AI to truly “know” an entity, it must be able to corroborate information across the web. This is where the sameAs and about properties become indispensable. The sameAs property establishes definitive links between an entity on your site and its corresponding authoritative representations elsewhere, such as Wikipedia, Wikidata, official social media profiles, or industry-specific registries.
When you declare your Organization or Person schema using sameAs to point to a verified Wikipedia page, you provide AI with a powerful signal of identity and authority. This helps disambiguate entities with similar names and consolidates information into a single, cohesive knowledge graph entry. It is a critical component for building E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) signals. For Planik.io, ensuring that its Organization schema sameAs links to its official Crunchbase profile and social media accounts reinforces its digital identity and credibility.
The about property defines the primary subject or topic of a piece of content. While sameAs is for entity identification, about provides contextual relevance. An Article about a new AI algorithm might use about to link to the Wikipedia entry for “Artificial Intelligence.” This tells AI precisely what the content is discussing, helping it categorize the information for relevant topical queries.
Customizing Schema for Specific Industry Niches
While generic schema types like Article or Product are foundational, AI search thrives on specificity. The power of structured data for niche industries lies in leveraging specialized types available within Schema.org. Instead of forcing unique offerings into a generic mold, you can provide AI with precise semantic context that matches your business model.
For example, a medical practice should implement MedicalClinic or Physician schema, detailing medicalSpecialty, acceptedInsurance, and hospitalAffiliation. A restaurant benefits from Restaurant schema, including servesCuisine, hasMenu, and acceptsReservations. Specialized types like SoftwareApplication, JobPosting, Event, FAQPage, and HowTo offer rich properties tailored to specific use cases.
Customizing schema means exploring the Schema.org hierarchy to find the most granular representation of your content. This specificity helps AI categorize your content correctly and enables it to surface your offerings for targeted, long-tail queries.
Pro Tip: When customizing schema for a niche, analyze competitor structured data using tools like the Rich Results Test. Identify common patterns and unique implementations, then explore the Schema.org vocabulary for your industry to identify high-impact opportunities.
Implementing Semantic Mapping to Align Website Content with Schema.org Vocabulary
Implementing advanced structured data is a strategic exercise in semantic mapping. This involves aligning the concepts, entities, and relationships in your content with the standardized vocabulary of Schema.org. It is about consciously structuring your content to maximize its interpretability by AI.
The initial step is to conduct a content inventory and entity identification. For every page, identify all primary and secondary entities (products, people, organizations, locations, topics) and their interrelationships. For instance, an article on “Sustainable Web Design” might feature Person (the author), Organization (the publisher, Planik.io), and Concept (design principles).
Once identified, these elements are mapped to the most appropriate Schema.org types. The outcome is a blueprint for your JSON-LD implementation, ensuring that your content’s semantic intent is perfectly translated into a machine-readable format.
To learn more about the technical steps, see our schema implementation technical guide
The Planik.io Semantic Blueprint Process:
- Identify Core Entities & Concepts: List primary subjects and distinguish between the main subject and supporting entities.
- Map to Schema.org Types: Select the most specific and relevant Schema.org type (e.g.,
LocalBusiness > Restaurant,Article > TechArticle). - Define Relationships & Properties: Map interactions to appropriate properties (e.g.,
author,offers,mentions) and identify nesting opportunities. - Establish External Connections (
sameAs,about): Identify authoritative external URLs to link viasameAsandabout. - Plan for Nesting: Visualize how complex relationships will be structured using nested JSON-LD objects.
- Iterate & Refine: Continuously review and update the mapping as content evolves, new schema types emerge, or business offerings change.
Ensuring Data Consistency Across Multi-Channel Digital Footprints
AI search engines aggregate information from many sources to build a comprehensive understanding of entities. Your website’s structured data is just one piece of this puzzle. To maximize AI comprehension, it is paramount to ensure data consistency across your entire multi-channel digital footprint. Discrepancies in entity information can confuse AI algorithms and dilute authority signals.
Key areas to audit and synchronize include:
- Google Business Profile (GBP): Ensure name, address, phone number (NAP), and website URL precisely match your structured data.
- Social Media Profiles: Verify that the organization name,
sameAslinks, and business descriptions on LinkedIn, Facebook, and X/Twitter align. - Third-Party Directories: Check listings on Yelp and industry-specific directories (e.g., Capterra for Planik.io).
- Press Releases: Monitor how your entity is referenced in external publications to ensure identifying details are accurate.
If Planik.io’s Organization schema lists a specific address, but its LinkedIn page shows an outdated one, AI may struggle to identify the canonical entity. This inconsistency can lead to fragmented knowledge graph entries and reduced visibility. Implementing a rigorous internal audit process to cross-reference these data points is crucial for maintaining digital credibility.

Solving Technical Hurdles: Ensuring AI Crawlers Can Access Your Data
The Pitfalls of Client-Side Rendering for Structured Data
While JavaScript-driven client-side rendering (CSR) offers dynamic user experiences, it presents technical hurdles for AI crawlers. Relying on JavaScript to inject JSON-LD markup can lead to inconsistent data ingestion. AI crawlers have varying capabilities for executing JavaScript, which often results in rendering delays or failure to process the structured data entirely, leaving valuable semantic context undiscovered.
Technical data suggests that when structured data is generated client-side, there is a higher risk of it being missed entirely by AI systems that prioritize speed and efficiency. For structured data for AI search, where explicit data cues are paramount, this unreliability is a critical impediment.
Ensuring Reliable Delivery with Server-Side Rendering
To circumvent the unreliability of client-side rendering, Server-Side Rendering (SSR) emerges as a robust solution. SSR ensures that your JSON-LD markup is fully present in the HTML response delivered directly from the server. This guarantees predictable and complete data delivery to AI crawlers, irrespective of their JavaScript rendering capabilities.
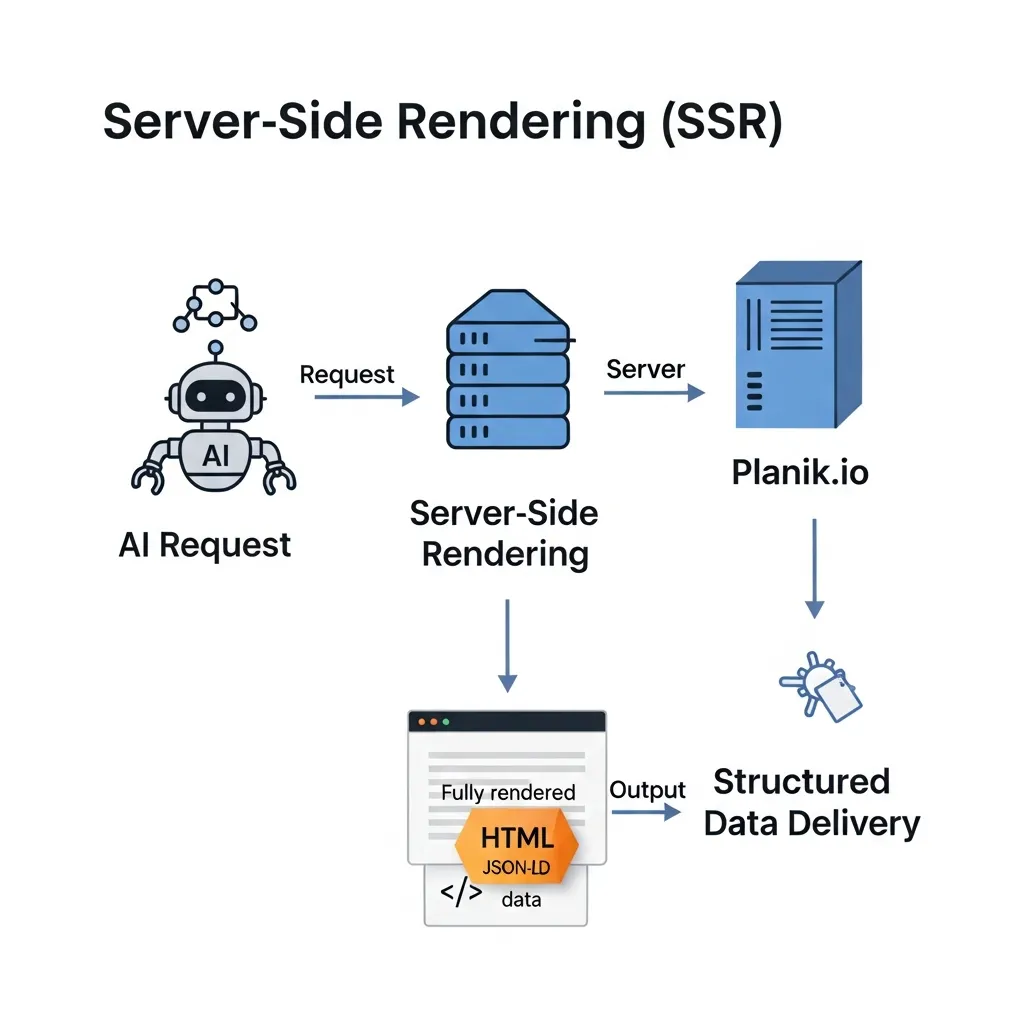
With SSR, the structured data is available in the initial page load, providing an immediate signal to AI systems about your content’s semantic relationships. This approach not only enhances discoverability but also contributes to faster initial page processing, improving overall site efficiency for semantic indexing.
Architecting for Semantic Crawler Efficiency
Beyond the rendering method, a well-optimized site architecture ensures AI crawlers can efficiently access your data. A clear, logical internal linking structure helps crawlers traverse your site systematically. Observations confirm that a flat site hierarchy, coupled with robust internal linking, facilitates a more comprehensive crawling process for AI systems.
Furthermore, maintaining accurate XML sitemaps serves as a roadmap for crawlers, guiding them directly to pages containing valuable structured data. Proper canonicalization is also essential to prevent AI crawlers from encountering duplicate content issues. By optimizing your site architecture, you create an environment where advanced JSON-LD nesting can be fully discovered and leveraged by AI search engines.
Building Authority: The Intersection of Structured Data and E-E-A-T
The drive for E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) is paramount in modern search. Structured data serves as an essential mechanism for AI to algorithmically assess these signals. Unlike traditional ranking factors, AI models explicitly consume structured markup to validate content credibility, particularly the ‘Trustworthiness’ pillar.
A key component of this strategy is to optimize blog posts with article schema
Verifying Expertise with Author Markup
To establish ‘Experience’ and ‘Expertise’, content creators must leverage Person and Organization schema. Marking up author profiles with attributes such as alumniOf, hasOccupation, and worksFor provides AI with verifiable credentials. Linking to professional profiles (e.g., LinkedIn, ORCID) via sameAs attributes further strengthens these signals. This allows AI to cross-reference an author’s qualifications against authoritative sources, enhancing the content’s overall authority.
Structuring Citations for Semantic Depth
The ‘Authoritativeness’ of content is amplified by transparent referencing. Implementing citation properties within WebPage schema or utilizing isBasedOn for CreativeWork types allows AI models to trace the foundational sources of information. By connecting content to scholarly articles or official reports, you build a verifiable knowledge graph. AI prioritizes content that demonstrably builds upon reputable sources.
Explicit Trust Signals for AI Models
Structured data directly validates ‘Trustworthiness’. When credentials are explicitly defined and content is transparently linked to authoritative sources, AI systems receive clear signals of credibility. This structural validation helps AI differentiate between speculative content and well-researched information. For AI, structured E-E-A-T signals are direct declarations of reliability, crucial for prominence in AI-driven search results.
In addition to these signals, you can boost credibility with review schema
Strategic Maintenance: Validating and Auditing Your Semantic Footprint
Implementing structured data is only the first step; its efficacy hinges on strategic maintenance. Stale or incorrect schema can be as detrimental as its absence, leading to misinterpretation. Continuous validation is paramount. Tools like Google’s Rich Results Test and the Schema.org Validator are essential for ad-hoc checks, providing immediate feedback on syntax and potential issues.
To maintain high-quality data, it is vital to understand the broader context of performing regular schema validation
However, manual checks are insufficient for dynamic sites. As content evolves, schema drift becomes a concern, where structured data falls out of sync with the page’s actual content. Automated monitoring solutions are crucial. These systems routinely crawl and re-validate schema against live content, flagging discrepancies. A product price update, for instance, must be reflected in the Offer schema to prevent AI models from surfacing outdated information. Planik.io offers features to track these changes, ensuring semantic data remains accurate.
A proactive approach also involves competitor analysis to identify schema gaps and opportunities. Observing top-ranking competitors for AI-driven queries can reveal sophisticated schema implementations you might be overlooking. Analyze not just what schema types they use, but how they have nested and contextualized the information. This intelligence can highlight missing attributes or richer entity connections that AI models favor, guiding your enhancement strategy.
Common Pitfalls and Professional Best Practices
Misapplication of structured data can lead to significant drawbacks. Deploying ‘schema spam’, or irrelevant and misleading markup, is increasingly detected by sophisticated AI search systems. AI’s advanced pattern recognition identifies manipulative practices, potentially resulting in ignored markup or algorithmic penalties. Professional implementation prioritizes authenticity, ensuring structured data accurately reflects genuine on-page content.
Maintaining this accuracy often involves identifying and resolving technical issues through troubleshooting schema markup errors
A critical balance must be maintained between human-readable content and machine-readable data. Structured data provides AI with explicit context for information already present and valuable to users; it is not a substitute for well-crafted, engaging content. AI search engines prioritize user experience, which is inherently reliant on high-quality, comprehensive content.
Ultimately, structured data functions as a support pillar for AI comprehension, not a replacement for foundational quality. Its role is to clarify and connect your existing information, enabling AI to surface it more effectively for relevant queries. Embracing these best practices ensures long-term semantic authority, a principle Planik.io champions for robust digital presences.
Future-Proofing Your Digital Presence for the AI Era
Structured data is not merely a tactical enhancement; it’s a foundational investment for enduring digital relevance. It ensures your content remains intelligible to evolving AI search agents, securing a future-proof presence. Sustained semantic optimization is crucial, requiring a proactive approach to adapting strategies as AI models advance. The SEO professional’s role is evolving into a strategic data architect, utilizing structured data for AI search to guide AI comprehension through precise markup. This continuous commitment ensures long-term visibility. To begin leveraging these insights, start now with step 1: audit your existing structured data for AI relevance.
FAQ
Why is structured data important for AI search?
Structured data provides machine-readable context that helps AI search engines and LLMs understand entities, relationships, and intent, moving beyond simple keyword matching to build comprehensive knowledge graphs.
What is the best format for implementing structured data for AI?
JSON-LD is the industry-standard format. It is highly flexible, allows for complex nesting of entity relationships, and is the preferred format for major search engines and AI crawlers.
How does structured data impact E-E-A-T signals?
Structured data allows you to explicitly define author credentials (via Person schema), organizational authority, and citations. This provides AI with verifiable signals of Expertise, Experience, Authoritativeness, and Trustworthiness.
Should I use client-side or server-side rendering for my schema?
Server-side rendering (SSR) is highly recommended. It ensures that JSON-LD markup is immediately available in the HTML response, preventing AI crawlers from missing data due to JavaScript execution delays.
What are the most critical schema types for AI visibility?
Key types include Organization and Person for entity identity, Product and Review for transactional queries, and FAQPage and HowTo for capturing featured AI Overviews and direct answer snippets.